> For the complete documentation index, see [llms.txt](https://amartyushov.gitbook.io/tech/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://amartyushov.gitbook.io/tech/databases/decision-guidance.md).
# Decision guidance
Below text is from article [LINK](https://medium.baqend.com/nosql-databases-a-survey-and-decision-guidance-ea7823a822d)
Every significantly successful database is designed for a particular class of applications, or to achieve a specific combination of desirable system properties. The simple reason why there are so many different database systems is that it is not possible for any system to achieve all desirable properties at once. Traditional SQL databases such as PostgreSQL have been built to provide the full functional package: a very flexible data model, sophisticated querying capabilities including joins, global integrity constraints and transactional guarantees. On the other end of the design spectrum, there are key-value stores like Dynamo that scale with data and request volume and offer high read and write throughput as well as low latency, but barely any functionality apart from simple lookups.
In this section, we highlight the design space of distributed database systems, concentrating on sharding, replication, storage management and query processing. We survey the available techniques and discuss how they are related to different functional and non-functional properties (goals) of data management systems. In order to illustrate what techniques are suitable to achieve which system properties, we provide the **NoSQL Toolbox** where each technique is connected to the functional and non-functional properties it enables (positive edges only).
## Sharding
Several distributed relational database systems such as Oracle RAC or IBM DB2 pureScale rely on a **shared-disk architecture** where all database nodes access the same central data repository (e.g. a NAS or SAN). Thus, these systems provide consistent data at all times, but are also inherently difficult to scale. In contrast, the (NoSQL) database systems focused in this paper are built upon a **shared-nothing architecture**, meaning each system consists of many servers with private memory and private disks that are connected through a network. Thus, high scalability in throughput and data volume is achieved by **sharding** (partitioning) data across different nodes (**shards**) in the system. There are three basic distribution techniques: range-sharding, hash-sharding and entity-group sharding. To make efficient scans possible, the data can be partitioned into ordered and contiguous value ranges by **range-sharding**. However, this approach requires some coordination through a master that manages assignments. To ensure elasticity, the system has to be able to detect and resolve hotspots automatically by further splitting an overburdened shard.
{% hint style="info" %}
Range sharding: :thumbsup:**data scans**!!, but needs :thumbsdown:**coordination** through master for new assignments.
{% endhint %}
Range sharding is supported by wide-column stores like [BigTable](http://static.googleusercontent.com/media/research.google.com/de//archive/bigtable-osdi06.pdf), HBase or Hypertable and document stores, e.g. MongoDB, RethinkDB, [Espresso](http://www.csce.uark.edu/~xintaowu/BDAM/p1135-qiao.pdf) and [DocumentDB](http://www.vldb.org/pvldb/vol8/p1668-shukla.pdf). Another way to partition data over several machines is **hash-sharding** where every data item is assigned to a shard server according to some hash value built from the primary key. This approach does not require a coordinator and also guarantees the data to be evenly distributed across the shards, as long as the used hash function produces an even distribution. The obvious disadvantage, though, is that it only allows lookups and makes scans unfeasible. Hash sharding is used in key-value stores and is also available in some wide-coloumn stores like [Cassandra](https://www.cs.cornell.edu/projects/ladis2009/papers/lakshman-ladis2009.pdf) or [Azure Tables](http://sigops.org/sosp/sosp11/current/2011-Cascais/printable/11-calder.pdf).
{% hint style="info" %}
Hash sharding: :thumbsup:**no coordination** and data is :thumbsup:**evenly distributed**, :thumbsdown:**no data scans**.
{% endhint %}
The shard server that is responsible for a record can be determined as serverid = hash(id)%servers, for example. However, this hashing scheme requires all records to be reassigned every time a new server joins or leaves, because it changes with the number of shard servers (servers). Consequently, it infeasible to use in elastic systems like Dynamo, Riak or Cassandra, which allow additional resources to be added on-demand and again be removed when dispensable. For **increased flexibility**, elastic systems typically use [**consistent hashing**](https://www.akamai.com/es/es/multimedia/documents/technical-publication/consistent-hashing-and-random-trees-distributed-caching-protocols-for-relieving-hot-spots-on-the-world-wide-web-technical-publication.pdf) where records are not directly assigned to servers, but instead to logical partitions which are then distributed across all shard servers. Thus, only a fraction of the data have to be reassigned upon changes in the system topology. For example, an elastic system can be downsized by offloading all logical partitions residing on a particular server to other servers and then shutting down the now idle machine. For details on how consistent hashing is used in NoSQL systems, see [the Dynamo paper](http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf).
**Entity-group sharding is a data partitioning scheme with the goal of enabling single-partition transactions on co-located data.** The partitions are called entity-groups and either explicitly declared by the application (e.g. in [G-Store](http://www.cs.ucsb.edu/~sudipto/papers/socc10-das.pdf) and [MegaStore](http://static.googleusercontent.com/media/research.google.com/de//pubs/archive/36971.pdf)) or derived from transactions’ access patterns (e.g. in [Relational Cloud](http://nms.lcs.mit.edu/papers/relcloud_cidr11.pdf) and [Cloud SQL Server](http://dl.acm.org/citation.cfm?id=2005651)). If a transaction accesses data that spans more than one group, data ownership can be transferred between entity-groups or the transaction manager has to fallback to more expensive multi-node transaction protocols.
## Replication
In terms of CAP, conventional RDBMSs are often CA systems run in single-server mode: The entire system becomes unavailable on machine failure. And so system operators secure data integrity and availability through expensive, but reliable high-end hardware. In contrast, NoSQL systems like Dynamo, BigTable or Cassandra are designed for data and request volumes that cannot possibly be handled by one single machine, and therefore they run on clusters consisting of thousands of servers. (Low-end hardware is used, because it is substantially more cost-efficient than high-end hardware.) Since [failures are inevitable and will occur frequently in any large-scale distributed system](https://www.usenix.org/legacy/event/lisa07/tech/full_papers/hamilton/hamilton_html/), the software has to cope with them on a daily basis . In 2009, Google fellow [Jeff Dean stated](https://www.cs.cornell.edu/projects/ladis2009/talks/dean-keynote-ladis2009.pdf) that a typical new cluster at Google encounters thousands of hard drive failures, 1,000 single-machine failures, 20 rack failures and several network partitions due to expected and unexpected circumstances in its first year alone. [Many more recent cases of network partitions and outages](https://aphyr.com/posts/288-the-network-is-reliable) in large cloud data centers have been reported. Replication allows the system to maintain availability and durability in the face of such errors. But storing the same records on different machines (**replica servers**) in the cluster introduces the problem of synchronization between them and thus a trade-off between consistency on the one hand and latency and availability on the other.
[Gray et al.](http://db.cs.berkeley.edu/cs286/papers/dangers-sigmod1996.pdf) propose a two-tier classification of different replication strategies according to *when* updates are propagated to replicas and *where* updates are accepted. There are two possible choices on tier one (“when”): **Eager**(*synchronous*) replication propagates incoming changes synchronously to all replicas before a commit can be returned to the client, whereas **lazy** (*asynchronous*) replication applies changes only at the receiving replica and passes them on asynchronously. The great advantage of *eager* replication is consistency among replicas, but it comes at the cost of higher write latency due to the need to wait for other replicas and impaired availability. *Lazy* replication is faster, because it allows replicas to diverge; as a consequence, stale data might be served. On the second tier (“where”), again, two different approaches are possible: Either a **master-slave** (*primary copy*) scheme is pursued where changes can only be accepted by one replica (the master) or, in a **update anywhere** (*multi-master*) approach, every replica can accept writes. In *master-slave* protocols, concurrency control is not more complex than in a distributed system without replicas, but the entire replica set becomes unavailable, as soon as the master fails. Multi-master protocols require complex mechanisms for prevention or detection and reconciliation of conflicting changes. Techniques typically used for these purposes are versioning, vector clocks, gossiping and read repair (e.g. in [Dynamo](http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf)) and [convergent or commutative datatypes](http://hal.upmc.fr/inria-00555588/document) (e.g. in Riak).
Basically, all four combinations of the two-tier classification are possible. Distributed relational systems usually perform *eager master-slave* replication to maintain strong consistency. *Eager update anywhere* replication as for example featured in Google’s Megastore suffers from a heavy communication overhead generated by synchronisation and can cause distributed deadlocks which are expensive to detect. NoSQL database systems typically rely on *lazy* replication, either in combination with the master-slave (CP systems, e.g. HBase and MongoDB) or the update anywhere approach (AP systems, e.g. Dynamo and Cassandra). Many NoSQL systems leave the choice between latency and consistency to the client, i.e. for every request, the client decides whether to wait for a response from any replica to achieve minimal latency or for a certainly consistent response (by a majority of the replicas or the master) to prevent stale data.
An aspect of replication that is not covered by the two-tier scheme is the **distance between replicas**. The obvious advantage of placing replicas near one another is low latency, but close proximity of replicas might also reduce the positive effects on availability; for example, if two replicas of the the same data item are placed in the same rack, the data item is not available on rack failure in spite of replication. But more than the possibility of mere temporary unavailability, placing replicas nearby also bears the peril of losing all copies at once in a disaster scenario. An alternative technique for latency reduction is used in [Orestes](http://www.btw-2015.de/res/proceedings/Hauptband/Wiss/Gessert-The_Cache_Sketch-165.pdf), where data is cached close to applications using web caching infrastructure and cache coherence protocols.
Geo-replication can protect the system against complete data loss and improve read latency for distributed access from clients. *Eager geo-replication*, as implemented in [Megastore](http://static.googleusercontent.com/media/research.google.com/de//pubs/archive/36971.pdf), [Spanner](http://static.googleusercontent.com/media/research.google.com/de//archive/spanner-osdi2012.pdf), [MDCC](http://mdcc.cs.berkeley.edu/mdcc.pdf) and [Mencius](http://sysnet.ucsd.edu/~yamao/pub/mencius-osdi.pdf) achieve strong consistency at the cost of higher write latencies (typically 100ms to 600ms). With *lazy geo-replication* as in Dynamo, [PNUTS](http://www.cs.ucsb.edu/~agrawal/fall2009/PNUTS.pdf), [Walter](http://news.cs.nyu.edu/~jinyang/pub/walter-sosp11.pdf), [COPS](https://www.cs.cmu.edu/~dga/papers/cops-sosp2011.pdf), Cassandra and BigTable recent changes may be lost, but the system performs better and remains available during partitions. [Charron-Bost et al. (Chapter 12)](http://dl.acm.org/citation.cfm?id=2172338) and [Öszu and Valduriez (Chapter 13)](http://dl.acm.org/citation.cfm?id=293457) provide a comprehensive discussion of database replication.
{% hint style="info" %}
MongoDB: lazy master-slave replication; Range sharding
{% endhint %}
{% hint style="info" %}
Cassandra: lazy update anywhere replication; Hash sharding
{% endhint %}
### 3.3 Storage Management
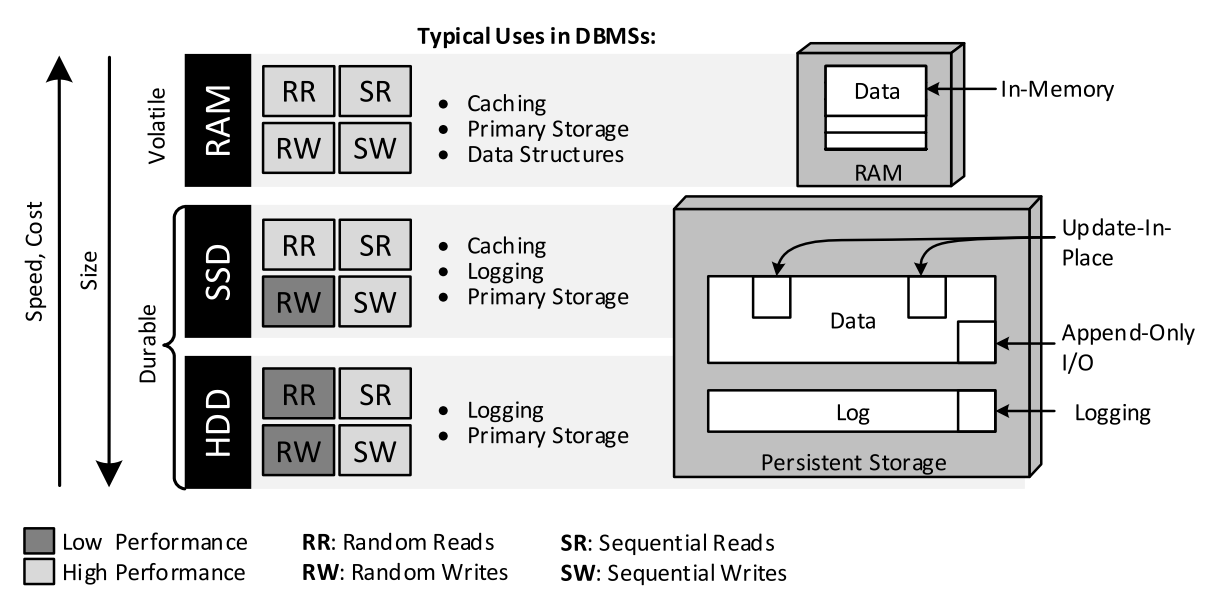
For best performance, database systems need to be optimized for the storage media they employ to serve and persist data. These are typically main memory (RAM), solid-state drives (SSDs) and spinning disk drives (HDDs) that can be used in any combination. Unlike RDBMSs in enterprise setups, distributed NoSQL databases avoid specialized shared-disk architectures in favor of shared-nothing clusters based on commodity servers (employing commodity storage media). Storage devices are typically visualized as a “storage pyramid” (see [Figure 5](https://medium.baqend.com/nosql-databases-a-survey-and-decision-guidance-ea7823a822d#fig:storage_model) or [Hellerstein et al.](http://db.cs.berkeley.edu/papers/fntdb07-architecture.pdf)). There is also a set of transparent caches (e.g. L1-L3 CPU caches and disk buffers, not shown in the Figure), that are only implicitly leveraged through well-engineered database algorithms that promote data locality. The very different cost and performance characteristics of RAM, SSD and HDD storage and the different strategies to leverage their strengths (storage management) are one reason for the diversity of NoSQL databases. Storage management has a spatial dimension (where to store data) and a temporal dimension (when to store data). Update-in-place and append-only-IO are two complementary spatial techniques of organizing data; in-memory prescribes RAM as the location of data, whereas logging is a temporal technique that decouples main memory and persistent storage and thus provides control over when data is actually persisted.
Figure 5: The storage pyramid and its role in NoSQL systems.
In their seminal paper [“the end of an architectural era”](http://nms.csail.mit.edu/~stavros/pubs/hstore.pdf), Stonebraker et al. have found that in typical RDBMSs, only 6.8% of the execution time is spent on “useful work”, while the rest is spent on:
* buffer management (34.6%), i.e. caching to mitigate slower disk access
* latching (14.2%), to protect shared data structures from race conditions caused by multi-threading
* locking (16.3%), to guarantee logical isolation of transactions
* logging (1.9%), to ensure durability in the face of failures
* hand-coded optimizations (16.2%)
This motivates that large performance improvements can be expected if RAM is used as primary storage (**in-memory databases**). The downside are high storage costs and lack of durability — a small power outage can destroy the database state. This can be solved in two ways: The state can be replicated over n in-memory server nodes protecting against n-1 single-node failures (e.g. [HStore](http://hstore.cs.brown.edu/papers/hstore-demo.pdf), VoltDB) or by **logging** to durable storage (e.g. Redis or SAP Hana). Through logging, a random write access pattern can be transformed to a sequential one comprised of received operations and their associated properties (e.g. redo information). In most NoSQL systems, the commit rule for logging is respected, which demands every write operation that is confirmed as successful to be logged and the log to be flushed to persistent storage. In order to avoid the rotational latency of HDDs incurred by logging each operation individually, log flushes can be batched together (group commit) which slightly increases the latency of individual writes, but drastically improves throughput.
SSDs and more generally all storage devices based on NAND flash memory differ substantially from HDDs in various aspects: “(1) asymmetric speed of read and write operations, (2) no in-place overwrite — the whole block must be erased before overwriting any page in that block, and (3) limited program/erase cycles” ([Min et al., 2012](https://www.usenix.org/legacy/events/fast12/tech/full_papers/Min.pdf)). Thus, a database system’s storage management must not treat SSDs and HDDs as slightly slower, persistent RAM, since random writes to an SSD are roughly an order of magnitude slower than sequential writes. Random reads, on the other hand, can be performed without any performance penalties. There are some database systems (e.g. Oracle Exadata, Aerospike) that are explicitly engineered for these performance characteristics of SSDs. In HDDs, both random reads and writes are 10–100 times slower than sequential access. Logging hence suits the strengths of SSDs and HDDs which both offer a significantly higher throughput for sequential writes.
For in-memory databases, an **update-in-place** access pattern is ideal: It simplifies the implementation and random writes to RAM are essentially equally fast as sequential ones, with small differences being hidden by pipelining and the CPU-cache hierarchy. However, RDBMSs and many NoSQL systems (e.g. MongoDB) employ an update-in-place update pattern for persistent storage, too. To mitigate the slow random access to persistent storage, main memory is usually used as a cache and complemented by logging to guarantee durability. In RDBMSs, this is achieved through a complex buffer pool which not only employs cache-replace algorithms appropriate for typical SQL-based access patterns, but also ensures ACID semantics. NoSQL databases have simpler buffer pools that profit from simpler queries and the lack of ACID transactions. The alternative to the buffer pool model is to leave caching to the OS through virtual memory (e.g. employed in MongoDB’s MMAP storage engine). This simplifies the database architecture, but has the downside of giving less control over which data items or pages reside in memory and when they get evicted. Also read-ahead (speculative reads) and write-behind (write buffering) transparently performed with OS buffering lack sophistication as they are based on file system logics instead of database queries.
**Append-only** storage (also referred to as log-structuring) tries to maximize throughput by writing sequentially. Although log-structured file systems have a long research history, append-only I/O has only recently been popularized for databases by BigTable’s use of Log-Structured Merge (LSM) trees consisting of an in-memory cache, a persistent log and immutable, periodically written storage files. LSM trees and variants like Sorted Array Merge Trees (SAMT) and Cache-Oblivious Look-ahead Arrays (COLA) have been applied in many NoSQL systems (Cassandra, CouchDB, LevelDB, Bitcask, RethinkDB, WiredTiger, RocksDB, InfluxDB, TokuDB). Designing a database to achieve maximum write performance by always writing to a log is rather simple, the difficulty lies in providing fast random and sequential reads. This requires an appropriate index structure that is either permanently updated as a copy-on-write (COW) data structure (e.g. CouchDB’s COW B-trees) or only periodically persisted as an immutable data structure (e.g. in BigTable-style systems). An issue of all log-structured storage approaches is costly garbage collection (compaction) to reclaim space of updated or deleted items.
In virtualized environments like Infrastructure-as-a-Service clouds many of the discussed characteristics of the underlying storage layer are hidden.
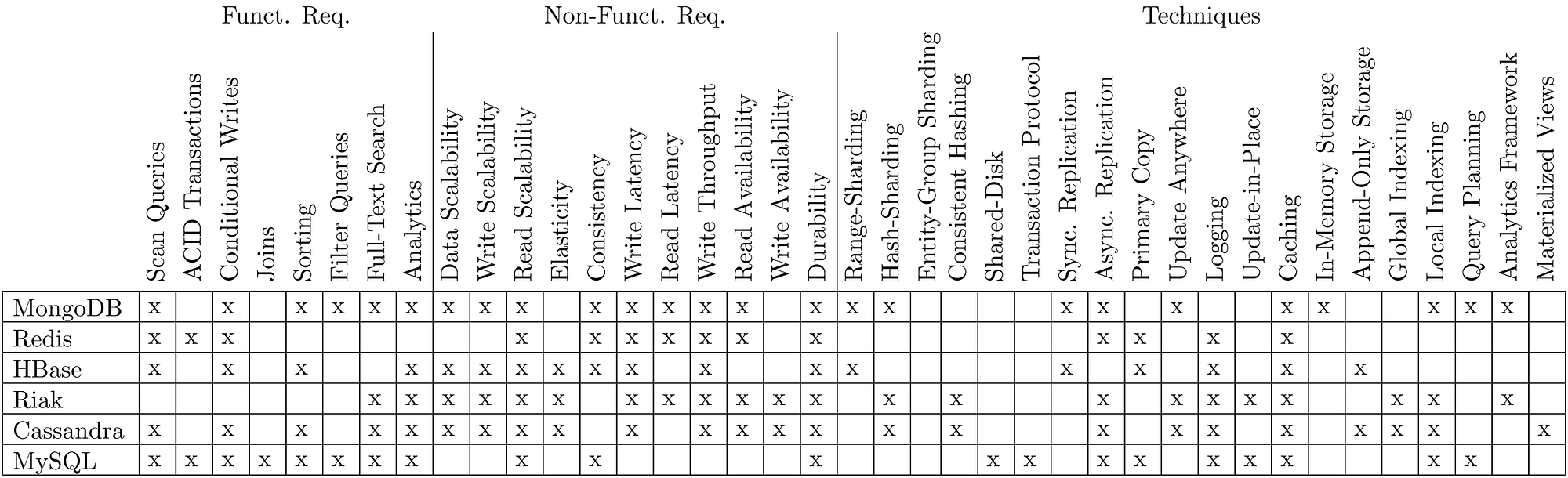
Table 1: A direct comparison of functional requirements, non-functional requirements and techniques among MongoDB, Redis, HBase, Riak, Cassandra and MySQL according to our NoSQL Toolbox.
### 3.4 Query Processing
The querying capabilities of a NoSQL database mainly follow from its distribution model, consistency guarantees and data model. **Primary key lookup**, i.e. retrieving data items by a unique ID, is supported by every NoSQL system, since it is compatible to range- as well as hash-partitioning. **Filter queries** return all items (or projections) that meet a predicate specified over the properties of data items from a single table. In their simplest form, they can be performed as *filtered full-table scans*. For hash-partitioned databases this implies a *scatter-gather* pattern where each partition performs the predicated scan and results are merged. For range-partitioned systems, any conditions on the range attribute can be exploited to select partitions.
To circumvent the inefficiencies of O(n) scans, secondary indexes can be employed. These can either be **local secondary indexes** that are managed in each partition or **global secondary indexes** that index data over all partitions. As the global index itself has to be distributed over partitions, consistent secondary index maintenance would necessitate slow and potentially unavailable commit protocols. Therefore in practice, most systems only offer eventual consistency for these indexes (e.g. Megastore, Google AppEngine Datastore, DynamoDB) or do not support them at all (e.g. HBase, Azure Tables). When executing global queries over local secondary indexes the query can only be targeted to a subset of partitions if the query predicate and the partitioning rules intersect. Otherwise, results have to be assembled through scatter-gather. For example, a user table with range-partitioning over an age field can service queries that have an equality condition on age from one partition whereas queries over names need to be evaluated at each partition. A special case of global secondary indexing is full-text search, where selected fields or complete data items are fed into either a database-internal inverted index (e.g. MongoDB) or to an external search platform such as ElasticSearch or Solr (Riak Search, DataStax Cassandra).
**Query planning** is the task of optimizing a query plan to minimize execution costs. For aggregations and joins, query planning is essential as these queries are very inefficient and hard to implement in application code. The wealth of literature and results on relational query processing is largely disregarded in current NoSQL systems for two reasons. First, the key-value and wide-column model are centered around CRUD and scan operations on primary keys which leave little room for query optimization. Second, most work on distributed query processing focuses on OLAP (online analytical processing) workloads that favor throughput over latency whereas single-node query optimization is not easily applicable for partitioned and replicated databases. However, it remains an open research challenge to generalize the large body of applicable query optimization techniques especially in the context of document databases. (Currently only RethinkDB can perform general Θ-joins. MongoDB’s aggregation framework has support for left-outer equi-joins in its aggregation framework and CouchDB allows joins for pre-declared map-reduce views.)
**In-database analytics** can be performed either natively (e.g. in MongoDB, Riak, CouchDB) or through external analytics platforms such as Hadoop, Spark and Flink (e.g. in Cassandra and HBase). The prevalent native batch analytics abstraction exposed by NoSQL systems is [MapReduce](http://static.googleusercontent.com/media/research.google.com/de//archive/mapreduce-osdi04.pdf). (An alternative to MapReduce are generalized **data processing pipelines**, where the database tries to optimize the flow of data and locality of computation based on a more declarative query language, e.g. MongoDB’s aggregation framework.) Due to I/O, communication overhead and limited execution plan optimization, these batch- and micro-batch-oriented approaches have high response times.**Materialized views** are an alternative with lower query response times. They are declared at design time and continuously updated on change operations (e.g. in CouchDB and Cassandra). However, similar to global secondary indexing, view consistency is usually relaxed in favor of fast, highly-available writes, when the system is distributed. As only few database systems come with built-in support for ingesting and querying unbounded streams of data,**near-real-time analytics** pipelines commonly implement either the [**Lambda Architecture**](http://lambda-architecture.net/) or the [**Kappa Architecture**](https://www.oreilly.com/ideas/questioning-the-lambda-architecture): The former complements a batch processing framework like Hadoop MapReduce with a stream processor such as Storm (see for example [Summingbird](http://www.vldb.org/pvldb/vol7/p1441-boykin.pdf)) and the latter exclusively relies on stream processing and forgoes batch processing altogether.
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://amartyushov.gitbook.io/tech/databases/decision-guidance.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.